Simple Deduplication (Theory)
Abstract
A commonly known cloud storage product is Dropbox. Previously (pre-2016), Dropbox utilized AWS for online storage and if you compare the pricing in late-2014, AWS charged $30/month for 1TB storage while Dropbox charged $9.99/month for 1TB storage. Just by looking at the prices, Dropbox is pretty much losing money. Then how did Dropbox generate revenue?
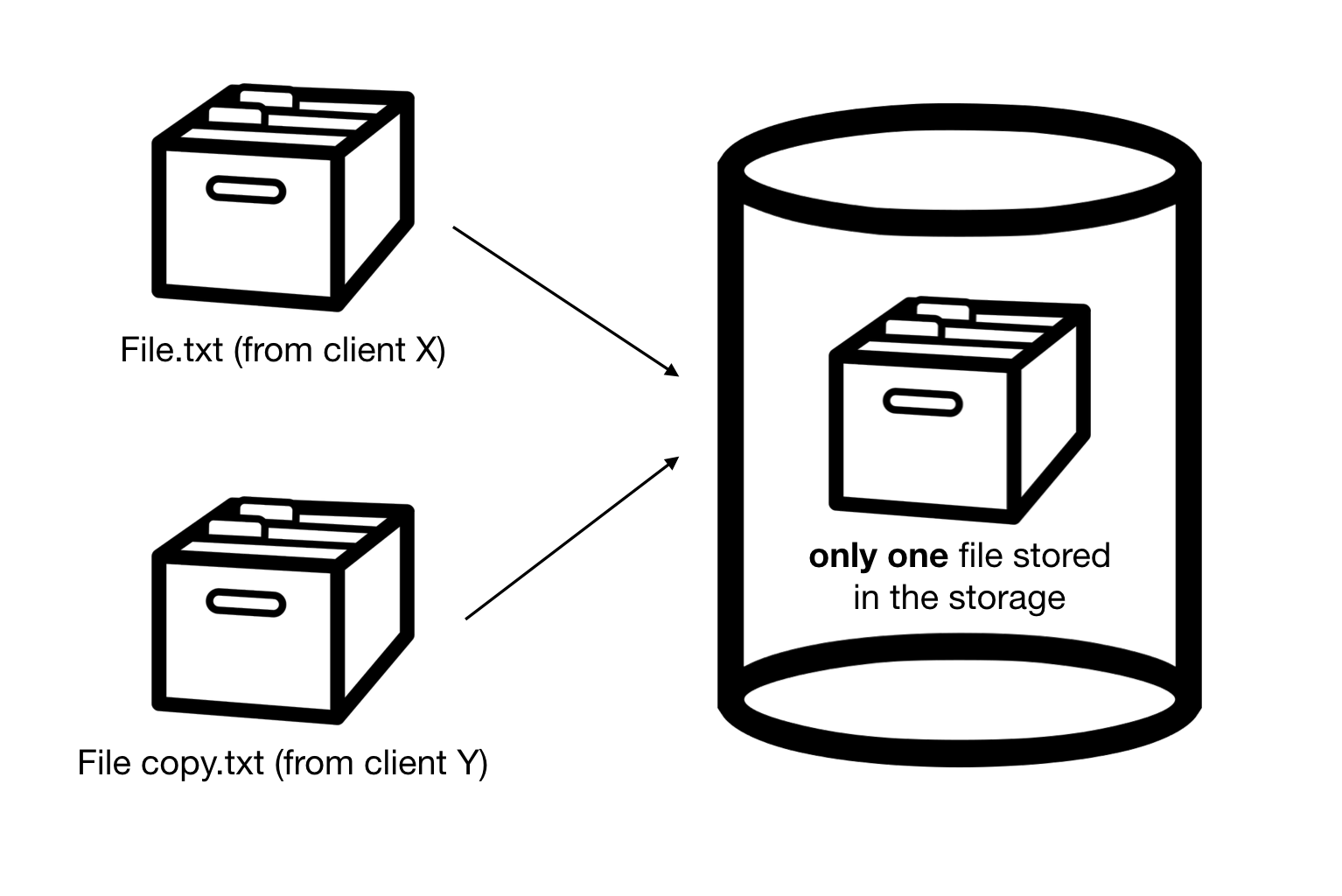
Deduplication is an approach that eliminates redundant data on storage. (i.e. instead of storing multiple copies of data of the same content, only one copy is stored).
Deduplication process can be reduced to 3 subprocesses: Chunking, Fingerprinting, and Indexing. Chunking is dividing data stream into different chunks. Fingerprinting is checking if the chunk is redundant (if new, upload chunk and fingerprint; if redundant, copy/upload the fingerprint). Indexing is maintaining fingerprints of existing chunks.
This post will only cover the basic idea of the concept and will not go in specific details (e.g. how Rabin Fingerprinting mathematically works). If the reader is interested in specific concepts, I strongly suggest to go search it up on the internet.
(Sidetrack) What about Compression?
While they both aim to reduce storage, deduplication is labelled as coarse-grained compression and basic compression that we are familiar with is labelled as fine-grained compression.
Chunking
Chunking in itself is a very simple process, but can become slightly complicated when additional optimizing techniques are integrated.
Chunking is basically a process where a file is separated into multiple smaller non-overlapping files.
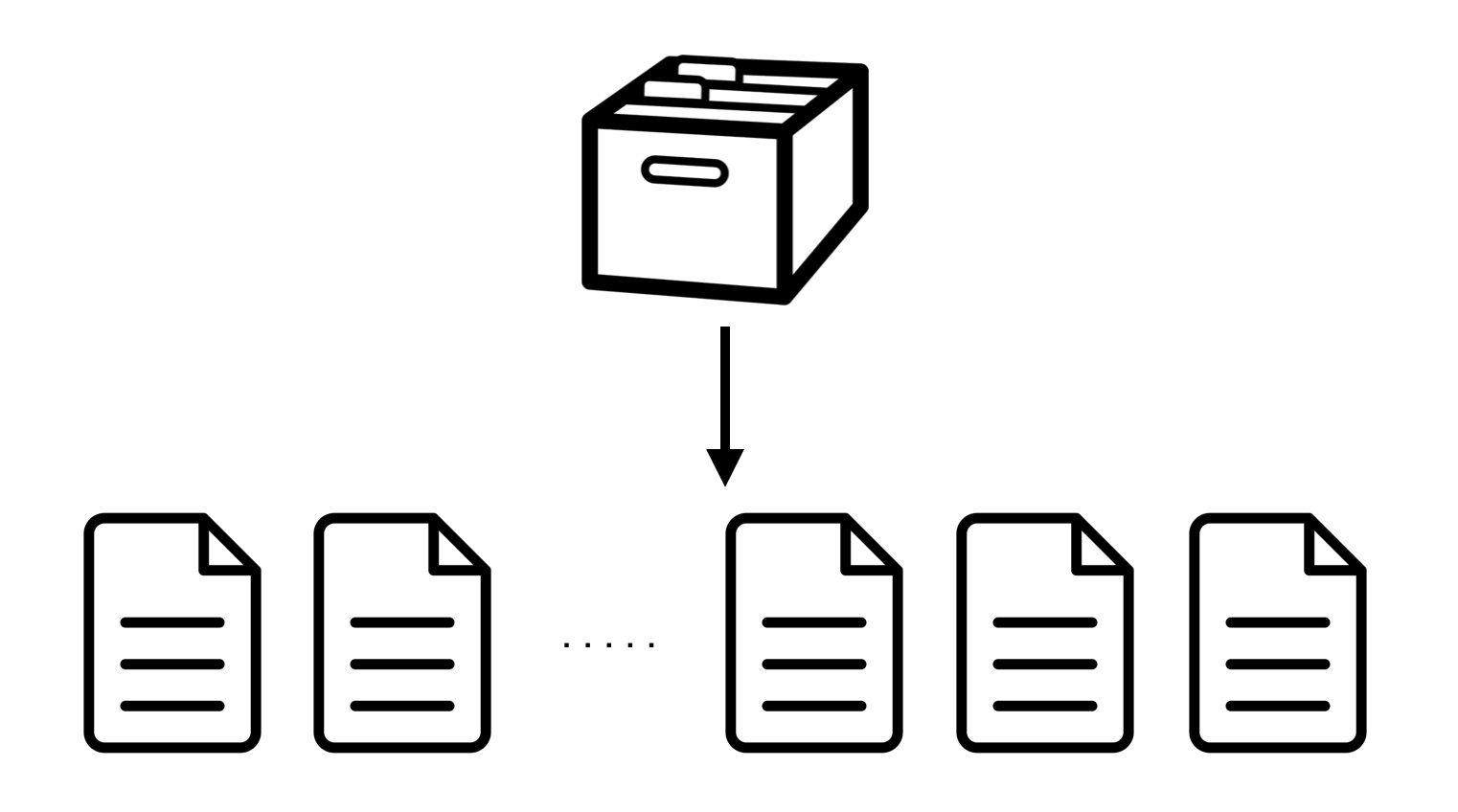
Splitting into multiple files is utilized because consider if you have a backup of some document, the current and the backup are usually not exactly the same. While they hold similar contents, perhaps names, dates, sentences, etc can be different. If someone deduplicated by the whole file itself, it would be inefficient because if the multiple documents (data) hold exactly the same contents but only different dates, they will be stored separately. In a sense, chunking is an optimization technique.
There is fixed sized chunking (where the chunk size is static), which does hold better efficiency for deduplication than the whole file deduplication, but the most effective one is variable size chunking (dynamic chunk size). Note that performing variable size chunking does use up more computation cost.
Fingerprinting
It is possible to check if the two files are the same by comparing byte by byte, but that is very inefficient. Instead a cryptographic hash (e.g. SHA-1, MD5, etc.) is done on the chunk and compared. This approach does create the risk of collision (i.e. same hash value for different files), but the chances are minuscule that hardware crash is more likely to happen than a hash collision (there are public research papers regarding this topic).
For deduplication, a specific type of fingerprinting, Rabin-Karp Algorithm (Rabin Fingerprinting), is commonly used. It’s basically a polynomial representation of data. The concept is slightly too complicated to go on length on a blog post, so I strongly suggest the readers to search it up on the internet to get a feel of what it is.
Indexing
After chunking → fingerprinting → comparing to know if it is new or redundant, it now faces a problem of keeping this fingerprints and chunks in the main storage system. Storing chunks is pretty straightforward, but fingerprints need to have good performance since it will be used frequently.
It is possible to store it on RAM, but for a 1TB storage + 4KB chunk + MD5 hash requires a 4GB worth of RAM. Since RAM are very expensive, it’s infeasible.
The next common storage (not known for performance) is disk. There are actually quite few ways to reduce the number of disk seeks to enhance the performance. Popular ones are: Bloom Filters, Sparse Indexing, and Extreme Binning.
Implementation
Go Simple Deduplication (Impementation), for the implementation post!
Comments